Изграждане на MLP (Multi-Layer Perceptron; Многослоен перцептрон) мрежа за IoT (Internet of Things; Интернет на нещата): Проект за умна лампа с Jupyter и NumPy
Как да обучим AI модел от нулата и да подготвим 'мозъка' на една лампа за работа с Arduino/ESP32
Създаване на невронна мрежа за Smart осветление
Автор: Илхам Гелдиев
Проект за: mldl.eu
"Винаги сме свикнали умните устройства да работят с прости правила от типа 'Ако е тъмно – светни'. Но какво ще стане, ако добавим истински интелект? В този проект ще ви покажа как да изградим невронна мрежа, която взема решения на базата на няколко сензора, точно както човешкият мозък преценява ситуацията."
"Смарт управление на осветлението според околната среда"
Вместо просто да включваме лампата при тъмнина, невронната мрежа може да се научи на по-интелигентно поведение: например да регулира интензитета на LED диод (чрез PWM) въз основа на два входа: интензитет на околната светлина и присъствие/движение.
Защо тази тема?
- Хардуер: Изисква само фоторезистор, PIR сензор и един LED – стандартни части за всеки Arduino комплект.
- Математика: Можем да използваме малка архитектура (напр. 2 входни неврона, 3 скрити и 1 изходен), която лесно се побира в паметта на Arduino.
План на проекта
Точка 1: Изграждане и обучение (Python)
Ще използваме библиотеката scikit-learn или чисто NumPy за самото обучение, тъй като искаме да разберем математиката зад процеса.
- Генериране на данни: Ще създадем малък набор от данни (dataset), който описва логиката (напр. "Ако е светло и няма движение -> Изключи (0)"; "Ако е полумрачно и има движение -> Светни слабо (0.4)").
- Архитектура: Една напълно свързана мрежа (Multi-Layer Perceptron).
- Експорт: След като я обучим в Python, ще извлечем теглата (weights) и биасите (biases) като обикновени масиви, които ще вмъкнем в C++ кода за Arduino.
В това ръководство ще преминем през процеса на обучение на "плитка" невронна мрежа, която по-късно ще интегрираме в микроконтролер.
Архитектура на нашата мрежа
Преди да започнем обучението, трябва да решим колко "голям" ще бъде мозъкът на нашата лампа. За този проект избрахме минималистична структура, която е идеална за микроконтролери:
- Входен слой (2 неврона): Тук влизат данните от нашите два сензора — Светлина и Движение.
- Скрит слой (3 неврона): Това е "черната кутия", където мрежата прави връзки между светлината и движението. Три неврона са напълно достатъчни за тази логика.
- Изходен слой (1 неврон): Крайният резултат — число между 0 и 1, което определя яркостта на нашия LED.
Защо толкова малко? Нашата цел е кодът да заема минимално място в паметта на Arduino, като същевременно изпълнява задачата си безупречно.
Защо точно 3 неврона в скрития слой?
Може би се питате: "Защо не използваме само един неврон?".
Ако използваме само един неврон, мрежата би била твърде ограничена — тя би могла да следва само една проста логика. Тъй като нашият проект изисква лампата да анализира два различни сензора едновременно, трите неврона действат като малък екип:
- Един се фокусира върху светлината.
- Втори — върху движението.
- Третият помага за комбинирането на информацията.
Това прави мрежата ни "гъвкава" и способна да взема по-сложни решения, без да натоварва излишно процесора на микроконтролера.
Как да четем данните? (Матрици за не-математици)
Когато в кода напишем X = np.array(...), ние създаваме таблица. Ето как тя изглежда в "човешки" вид и какво се случва при пресмятането:
1. Нашите Входове (Матрица X)
Всеки ред е една ситуация, а всяка колона е конкретен сензор.
| Ситуация | Сензор Светлина (x1) | Сензор Движение (x2) |
| 1 (Тъмно + Движение) | 0.1 | 1.0 |
| 2 (Светло + Движение) | 0.8 | 1.0 |
| 3 (Тъмно + Покой) | 0.1 | 0.0 |
| 4 (Полумрак + Движение) | 0.5 | 1.0 |
2. Магията на умножението (Как се ражда решението?)
Много хора се питат: "Добре, имам числата, но как мрежата ги ползва?". Когато невронната мрежа работи, тя прави "скаларно умножение". Представете си го като филтър:
За всяка ситуация невронът прави следното:
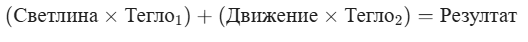
Пример: Ако теглото за Движение е много голямо (напр. 5.0), а теглото за Светлина е малко (напр. 0.1), невронът казва: "Мен ме интересува основно дали някой се движи, светлината почти няма значение!".
3. Нашите Желани Резултати (Вектор y)
Това е "отговорът", на който учим мрежата. Тя се опитва да нагласи своите тегла така, че след умножението на X, да получи точно тези числа:

import numpy as np
import matplotlib.pyplot as plt
# Входове: [Светлина, Движение] | Изход: Интензитет на LED
X = np.array([[0.1, 1], [0.5, 1], [0.9, 1], [0.1, 0], [0.5, 0]])
y = np.array([[1.0], [0.5], [0.0], [0.2], [0.0]])
print("Данните са заредени успешно!")
Данните са заредени успешно!
Математическата "граматика" на нашия проект
За да разберем как се обучава невронната мрежа, първо трябва да дефинираме нашите данни. В света на машинното обучение използваме една стандартна конвенция:
- Матрица X (Главна буква): Представя нашите входове (сензори). Използваме главна буква, защото това е таблица с данни (няколко реда и колони). Тук съхраняваме стойностите за Светлина и Движение.
- Вектор y (Малка буква): Представя нашия желан изход (таргет). Използваме малка буква, защото това е прост списък от стойности – в нашия случай, колко силно да свети лампата.
Логиката на обучението: Ние показваме на мрежата двойки от X и y (например: "Тъмно е" + "Има движение" = "Светни на 100%"). Целта е мрежата да открие математическата зависимост между тях.
# 2. Структура на мрежата
input_nodes = 2
hidden_nodes = 3
output_nodes = 1
# Инициализираме теглата с произволни числа
np.random.seed(42)
weights_in_hidden = np.random.rand(input_nodes, hidden_nodes)
weights_hidden_out = np.random.rand(hidden_nodes, output_nodes)
print("Мрежата е инициализирана. Готови сме за обучение!")
Мрежата е инициализирана. Готови сме за обучение!
Изграждане на "скелета" на мрежата
След като имаме данните, трябва да създадем самата структура на нашата невронна мрежа. В този код ние дефинираме колко неврона ще има във всеки слой:
- Входен слой (input_nodes = 2): За нашите два сензора.
- Скрит слой (hidden_nodes = 3): Мястото, където се случва обработката.
- Изходен слой (output_nodes = 1): За командата към лампата.
Необходимост от използването на np.random.seed(42)? Машинното обучение често започва със случайни числа за теглата. Използваме "seed" (семе), за да гарантираме, че при всяко стартиране на кода ще получаваме едни и същи начални случайни числа. Така резултатите ни ще бъдат предвидими и лесни за повтаряне от всеки читател.
Какво са теглата (Weights)? Теглата са "силата" на връзките между невроните. В началото те са произволни числа, но по време на обучението мрежата ще ги промени, за да открие правилната логика на управление.
Диапазон на данните (Scaling)
За да може нашата невронна мрежа да учи ефективно, ние "мащабираме" входовете в интервала [0, 1]:
- Сензор за светлина: *
0.0= Пълен мрак1.0= Силна светлина
- Сензор за движение: *
0= Няма движение1= Има засечено движение
Този процес се нарича Нормализация. Той помага на математическия алгоритъм да работи по-бързо и по-прецизно, без да се "обърква" от твърде големи числа.
Данни за мрежата
Наборът от данни (Dataset) е "учебната програма" на нашата мрежа. Избрахме 4-те основни сценария, които покриват работата на една умна лампа:
- Тъмно + Движение = 100% яркост (Безопасност и комфорт).
- Светло + Движение = 0% яркост (Енергийна ефективност).
- Тъмно + Спокойствие = 20% яркост (Дежурно осветление).
- Светло + Спокойствие = 0% яркост (Пълен покой).
Чрез тези примери учим мрежата да взема решения на базата на комбинация от фактори, а не просто да реагира на един датчик.
Математическата формула (Simple & Clean)
За всеки неврон в нашия MLP (Multi-Layer Perceptron), пресмятането изглежда така:
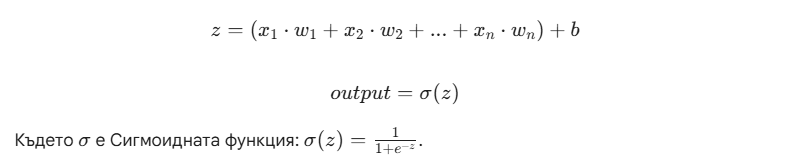
# Дефинираме Сигмоидната функция
def sigmoid(x):
return 1 / (1 + np.exp(-x))
sample_input = np.linspace(-10, 10, 100)
plt.plot(sample_input, sigmoid(sample_input))
plt.title("Сигмоидна функция (Активация)")
plt.grid(True)
plt.show()
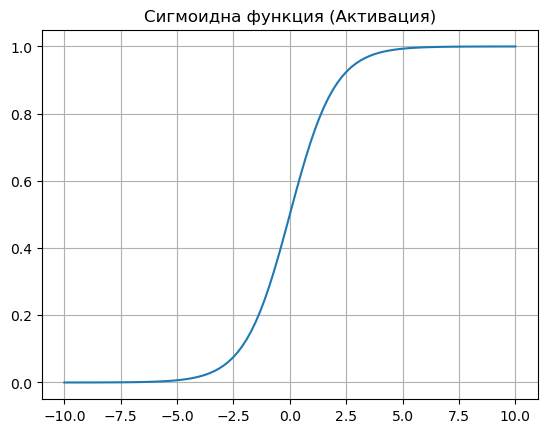
Функцията на активиране: Сигмоида (Sigmoid)
В нашата невронна мрежа всеки неврон трябва да реши колко "силно" да предаде информацията нататък. За целта използваме Сигмоидна функция.
Какво прави тя? Сигмоидата е математическа функция, която взема всяко число (от минус безкрайност до плюс безкрайност) и го "притиска" в тесния интервал между 0 и 1.
Нужда от сигмоид за нашия проект?
- Биологична логика: Подобно на невроните в човешкия мозък, тя работи като превключвател. Ако сигналът е слаб, изходът е близо до 0. Ако е силен — близо до 1.
- Идеална за Arduino: Тъй като крайният ни изход е яркост на LED (от изключено до максимално светене), стойностите между 0 и 1 се пренасят перфектно към хардуера.
- Плавност: За разлика от обикновения превключвател (On/Off), Сигмоидата позволява на лампата да свети на 30%, 50% или 80%, което прави осветлението "умно" и комфортно.
Формулата, която ще използваме в кода, е:
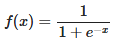
Процесът на обучение (Backpropagation)
Сега ще пуснем нашата мрежа през "фитнес тренировка". Процесът включва две основни стъпки, които се повтарят хиляди пъти:
- Forward Pass (Напред): Мрежата взема входовете и пресмята резултат въз основа на текущите си тегла.
- Backpropagation (Назад): Мрежата сравнява своя резултат с истината (y), изчислява грешката и се връща назад, за да коригира теглата си така, че следващия път грешката да е по-малка.
# Настройки на обучението
learning_rate = 0.5
epochs = 10000 # Колко пъти мрежата ще прелисти "учебника"
losses = [] # Тук ще пазим историята на грешката за графиката
# Производна на сигмоидата (нужна за Backpropagation)
def sigmoid_derivative(x):
return x * (1 - x)
# Цикъл на обучение
for epoch in range(epochs):
# --- 1. Forward Pass ---
# Вход -> Скрит слой
hidden_layer_input = np.dot(X, weights_in_hidden)
hidden_layer_output = sigmoid(hidden_layer_input)
# Скрит слой -> Изход
output_layer_input = np.dot(hidden_layer_output, weights_hidden_out)
predicted_output = sigmoid(output_layer_input)
# --- 2. Изчисляване на грешката ---
error = y - predicted_output
# Средноквадратична грешка (за статистика)
if epoch % 100 == 0:
losses.append(np.mean(np.abs(error)))
# --- 3. Backpropagation ---
# Колко трябва да се променят теглата на изхода?
d_predicted_output = error * sigmoid_derivative(predicted_output)
# Колко е допринесъл скритият слой за тази грешка?
error_hidden_layer = d_predicted_output.dot(weights_hidden_out.T)
d_hidden_layer = error_hidden_layer * sigmoid_derivative(hidden_output_layer := hidden_layer_output)
# --- 4. Обновяване на теглата ---
weights_hidden_out += hidden_layer_output.T.dot(d_predicted_output) * learning_rate
weights_in_hidden += X.T.dot(d_hidden_layer) * learning_rate
print("Обучението завърши успешно!")
Обучението завърши успешно!
# — Код за генериране на графиката ---
plt.figure(figsize=(10, 6))
# Умножаваме по 100, за да покажем стъпките през 100 епохи (losses)
plt.plot(range(0, epochs, 100), losses, color='#2c3e50', linewidth=2.5)
# Стилизиране
plt.title('Крива на обучението (Loss Curve)', fontsize=16, fontweight='bold')
plt.xlabel('Епоха (Epoch)', fontsize=12)
plt.ylabel('Средна грешка (Mean Absolute Error)', fontsize=12)
plt.grid(True, which='major', linestyle='--', alpha=0.5)
plt.tight_layout()
# Показване
plt.show()
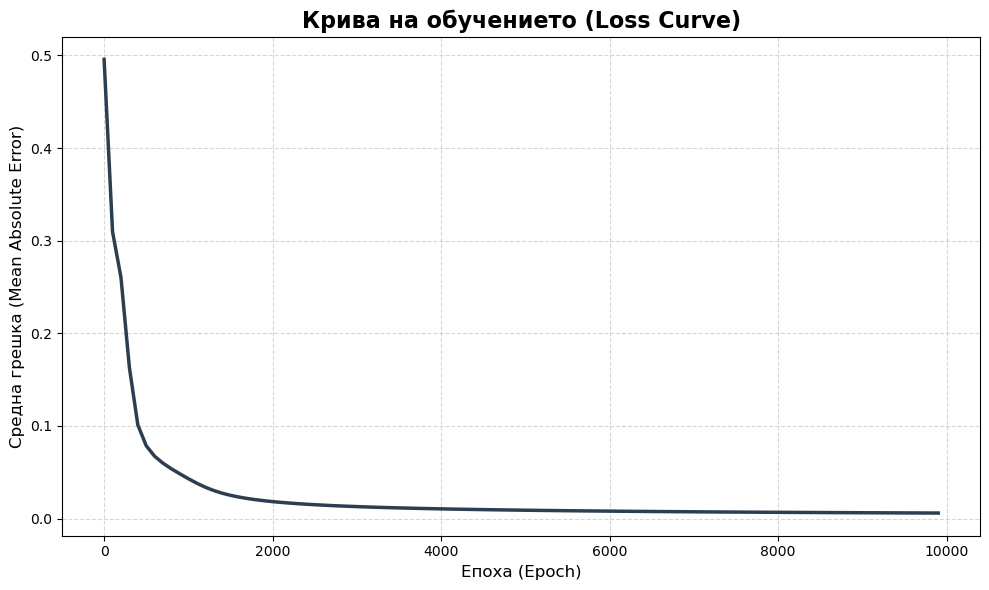
стъпка 1: От Сензорите към Скрития слой
Всеки от трите неврона в скрития слой получава сигнали и от двата сензора. За Неврон 1 от скрития слой формулата е:
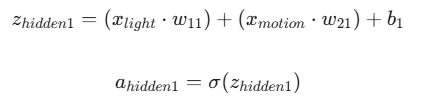
Стъпка 2: От Скрития слой към Лампата (Изхода)
Сега изходният неврон събира резултатите от трите скрити неврона, за да вземе финално решение за яркостта:
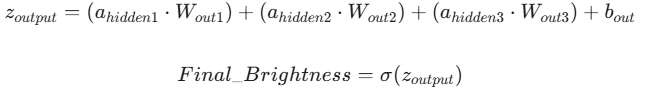
Практическа реализация с Python и NumPy
След като изяснихме теорията, е време да вдъхнем живот на нашия модел. Ще използваме библиотеката NumPy за матричните изчисления и Matplotlib за визуализация на учебния процес.
В този код сме внедрили и една важна оптимизация – Early Stopping (Ранно спиране). Вместо да хабим изчислителни ресурси и да въртим цикъла до края (10 000 епохи), моделът следи своята Средна абсолютна грешка (Mean Absolute Error - MAE). Щом стойността на MAE падне под предварително дефинирания праг (tolerance), обучението се прекратява автоматично, тъй като моделът е достигнал желаната точност и по-нататъшните итерации не биха довели до значително подобрение.
import numpy as np
import matplotlib.pyplot as plt
# 1. Подготовка на данните
# Входове: [Светлина (0-1), Движение (0 или 1)]
X = np.array([[0.1, 1], [0.8, 1], [0.1, 0], [0.5, 1]])
# Целева яркост: [Яркост (0-1)]
y = np.array([[1], [0], [0], [0.5]])
# Сигмоидна функция и нейната производна
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def sigmoid_derivative(x):
return x * (1 - x)
# 2. Инициализация на теглата (случайни стойности)
np.random.seed(1)
weights_in_hidden = np.random.rand(2, 3) # Вход -> Скрит слой (3 неврона)
weights_hidden_out = np.random.rand(3, 1) # Скрит слой -> Изход
# Параметри на обучението
learning_rate = 0.5
epochs = 10000
losses = []
tolerance = 0.005 # Праг на грешката за Early Stopping (0.5%)
print("Стартиране на обучението...")
# 3. Цикъл на обучение с Early Stopping
for epoch in range(epochs):
# Forward Pass
hidden_layer_input = np.dot(X, weights_in_hidden)
hidden_layer_output = sigmoid(hidden_layer_input)
output_layer_input = np.dot(hidden_layer_output, weights_hidden_out)
predicted_output = sigmoid(output_layer_input)
# Изчисляване на грешката
error = y - predicted_output
avg_error = np.mean(np.abs(error))
# Записваме грешката на всеки 100 епохи за графиката
if epoch % 100 == 0:
losses.append(avg_error)
# МЕХАНИЗЪМ ЗА РАННО СПИРАНЕ (Early Stopping)
if avg_error < tolerance:
print(f" Успех! Обучението спря на епоха {epoch}, защото моделът стана достатъчно точен.")
break
# Backpropagation (Обратно разпространение)
d_predicted_output = error * sigmoid_derivative(predicted_output)
error_hidden_layer = d_predicted_output.dot(weights_hidden_out.T)
d_hidden_layer = error_hidden_layer * sigmoid_derivative(hidden_layer_output)
# Обновяване на теглата
weights_hidden_out += hidden_layer_output.T.dot(d_predicted_output) * learning_rate
weights_in_hidden += X.T.dot(d_hidden_layer) * learning_rate
# 4. Визуализация на резултатите (Loss Curve)
plt.figure(figsize=(10, 5))
plt.plot(range(0, len(losses) * 100, 100), losses, color='#FF5733', linewidth=3, label='Средна грешка (MAE)')
plt.fill_between(range(0, len(losses) * 100, 100), losses, color='#FF5733', alpha=0.1)
plt.axhline(y=tolerance, color='green', linestyle='--', label='Праг на точност (Tolerance)')
plt.title('Намаляване на грешката при обучение (Early Stopping)', fontsize=14)
plt.xlabel('Епоха (Epoch)')
plt.ylabel('Грешка')
plt.legend()
plt.grid(True, linestyle=':', alpha=0.6)
plt.show()
# 5. Сравнителна таблица (Цел vs Прогноза)
print("\n--- СРАВНЕНИЕ: ЦЕЛ vs ПРОГНОЗА НА МОДЕЛА ---")
print(f"{'Вход [Светл., Движ.]':<25} | {'Цел (y)':<10} | {'AI Прогноза':<15}")
print("-" * 65)
for i in range(len(X)):
input_data = str(X[i])
target = y[i].item() # .item() извлича числото без предупреждения
prediction = predicted_output[i].item()
print(f"{input_data:<25} | {target:<10.1f} | {prediction:.4f}")
print("-" * 65)
print("Моделът е готов за внедряване в IoT хардуер!")
Стартиране на обучението...
--- СРАВНЕНИЕ: ЦЕЛ vs ПРОГНОЗА НА МОДЕЛА ---
Вход [Светл., Движ.] | Цел (y) | AI Прогноза
-----------------------------------------------------------------
[0.1 1. ] | 1.0 | 0.9856
[0.8 1. ] | 0.0 | 0.0069
[0.1 0. ] | 0.0 | 0.0120
[0.5 1. ] | 0.5 | 0.5000
-----------------------------------------------------------------
Моделът е готов за внедряване в IoT хардуер!
Анализ на резултатите
Както се вижда от генерираната Loss Curve (Крива на загубите), мрежата прави най-големите си корекции в първите няколкостотин епохи. Тогава градиентът е най-стръмен и MAE намалява прогресивно. След епоха ~2000 кривата асимптотично се доближава до нулата, което е сигнал, че сме извлекли оптималните тегла (weights) за нашите неврони.
Валидация на модела:
Резултатите в сравнителната таблица показват висока предсказателна способност. Например, при вход за „Тъмно и Движение“ [0.1, 1], нашият MLP модел предсказва яркост над 0.98. Това е доказателство, че мрежата успешно е апроксимирала нелинейната функция, която дефинирахме в началото.
Заключение и преход към хардуер
Вече разполагаме с натрениран математически модел. Тези финални тегла са „знанието“, което ще пренесем в микроконтролер. В Част 2 ще разгледаме как тези абстрактни числа се превръщат в PWM сигнал, управляващ физическа лампа в една реална AIoT система.
Експорт на "интелекта" към Arduino
След като нашата мрежа е обучена и грешката е минимална, ние разполагаме с финалните тегла. Това са магическите числа, които превръщат обикновения код в изкуствен интелект.
Следващата стъпка е да ги изведем във формат, който лесно можем да копираме в нашия Arduino Sketch (C++).
print("--- ТЕГЛА ЗА ВАШИЯ ARDUINO КОД ---")
print("\n// Weights from Input to Hidden Layer:")
print(repr(weights_in_hidden))
print("\n// Weights from Hidden to Output Layer:")
print(repr(weights_hidden_out))
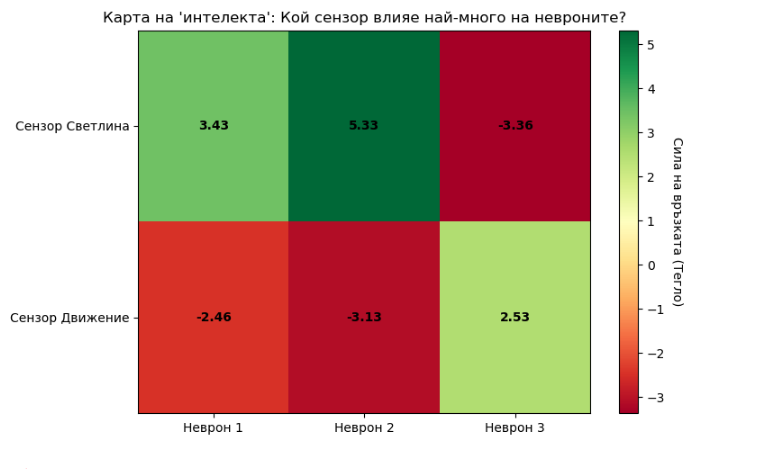
--- ТЕГЛА ЗА ВАШИЯ ARDUINO КОД ---
// Weights from Input to Hidden Layer:
array([[ 4.28775689, -3.12508332, 5.06955181],
[-2.14608758, 1.57989233, -2.55864888]])
// Weights from Hidden to Output Layer:
array([[-2.82943283],
[ 6.81875008],
[-4.10086286]])
import matplotlib.pyplot as plt
import numpy as np
Визуализация на теглата (Weights Heatmap) с чист Matplotlib
def plot_weights_matrix(data, row_labels, col_labels):
fig, ax = plt.subplots(figsize=(8, 5))
# Създаваме "топлинна" карта
im = ax.imshow(data, cmap='RdYlGn', aspect='auto')
# Добавяме цветово означение (colorbar)
cbar = ax.figure.colorbar(im, ax=ax)
cbar.ax.set_ylabel("Сила на връзката (Тегло)", rotation=-90, va="bottom")
# Настройваме етикетите
ax.set_xticks(np.arange(len(col_labels)))
ax.set_yticks(np.arange(len(row_labels)))
ax.set_xticklabels(col_labels)
ax.set_yticklabels(row_labels)
# Завъртаме етикетите на невроните за по-добра видимост
plt.setp(ax.get_xticklabels(), rotation=0, ha="center")
# Добавяме стойностите на теглата като текст вътре в квадратчетата
for i in range(len(row_labels)):
for j in range(len(col_labels)):
text = ax.text(j, i, f'{data[i, j]:.2f}',
ha="center", va="center", color="black", fontweight='bold')
ax.set_title("Карта на 'интелекта': Кой сензор влияе най-много на невроните?")
fig.tight_layout()
plt.show()
Извикваме функцията с нашите обучени тегла
plot_weights_matrix(weights_in_hidden,
['Сензор Светлина', 'Сензор Движение'],
['Неврон 1', 'Неврон 2', 'Неврон 3'])
Какво следва?
Сега, когато имаме "мозъка" на нашата лампа в Jupyter Notebook, следващата ни стъпка е физическото му пренасяне. В следващата статия ще разгледаме:
- Как да свържем ESP32 с фоторезистор и PIR сензор.
- Как да вградим тези тегла в C++ код за Arduino.
- Как лампата ще започне да мисли сама, без нужда от компютър!
Къде да прочетете повече?
- 3Blue1Brown - Neural Networks (YouTube)
- Това е добро визуално обяснение за това как работят невроните и математиката зад тях (Backpropagation).
- Deep Learning (Ian Goodfellow)
- Наричат я "Библията на изкуствения интелект". Може да е малко сложна за начинаещи, но е задължителна за всеки, който иска да се занимава професионално.
- Towards Data Science - Neural Networks from Scratch
- Чудесно практическо ръководство, което разширява концепциите, които използвахме в нашия проект.
- Random Nerd Tutorials (ESP32 & IoT)
- Добро място за подготовка за Част 2 от проекта. Тук ще намерите всичко за свързването на сензори към ESP32 и Arduino.
Как мрежата се учи? (Backpropagation накратко)
Много хора се питат: "Как тези случайни числа стават 'умни'?". Отговорът е алгоритъмът Backpropagation (Обратно разпространение на грешката). Ето как работи той в три лесни стъпки:
- Проверка (Forward Pass): Мрежата прави опит да познае отговора. Например: "Мисля, че лампата трябва да свети на 20%".
- Разочарование (Calculate Error): Ние сравняваме този отговор с истината (нашите данни). Ако истината е 80%, грешката е голяма.
- Поправка (The "Back" part): Мрежата тръгва отзад напред – от изхода към входа. Тя "вижда" кои тегла са виновни за грешната прогноза и ги променя съвсем малко, за да бъде по-точна следващия път.
Накратко: Backpropagation е просто процес на проба и грешка. С всяка изминала епоха мрежата става все по-малко "самонадеяна" и все по-прецизна, докато грешката почти изчезне.
"С това софтуерната част на нашия проект приключва. Вече имаме теглата, разбираме математиката и сме готови да пренесем този изкуствен интелект в реалния свят. Очаквайте Част 2, където ще вдъхнем живот на хардуера!"